BlastにおけるE-value(E値)の計算方法について
BLASTにおけるE-value(E値)とは何か?
一言でいうと、偶然この配列がデータベース内にある期待値です。
たとえばE-valueが1だとすると、データベース内に1本、偶然あたる配列があるということを示しています。
E-valueの計算方法
K × (クエリ配列中の塩基/アミノ酸の数) × (DB配列中の塩基/アミノ酸の数(合計値)) × e-λ×アライメントスコア
クエリとDBの配列が短いほどE-valueは大きく、アライメントスコアが大きいほどE-valueは小さくなります。
BLASTのE-valueの見方
ここではTCA回路のコハク酸からフマル酸に変換する酵素の遺伝子(succinate dehydrogenase)をNCBIのBLASTで検索してみます。
データはKEGGから適当に改変しています。
> seq1
atggcggcggtggtcgccctctccttgaggcgccggttgccggccacaacccttggcgga
gcctgcctgcaggcctcccgaggagcccagacagctgcagccacagctccccgtatcaag
aaatttgccatctatcgatgggacccagacaaggctggagacaaacctcatatgcagact
tatgaagttgaccttaataaatgtggccccatggtattggatgctttaatcaagattaag
aatgaagttgactctactttgaccttccgaagatcatgcagagaaggcatctgtggctct
tgtgcaatgaacatcaatggaggcaacactctagcttgcacccgaaggattgacaccaac
ctcaataaggtctcaaaaatctaccctcttccacacatgtatgtgataaaggatcttgtt
cccgatttgagcaacttctatgcacagtacaaatccattgagccttatttgaagaagaag
gatgaatctcaggaaggcaagcagcagtatctgcagtccatagaagagcgtgagaaactg
gacgggctctacgagtgcattctctgtgcctgctgtagcaccagctgccccagctactgg
tggaacggagacaaatatctggggcctgcagttcttatgcaggcctatcgctggatgatt
gactccagagatgacttcacagaggagcgcctggccaagctgcaggacccattctctcta
taccgctgccacaccatcatgaactgcacaaggacctgtcctaagggtctgaatccaggg
aaagctattgcagagatcaagaaaatgatggcaacctataaggagaagaaagcttcagtt
taa
1. 公式ページへ飛ぶ
公式ページ:BLASTN
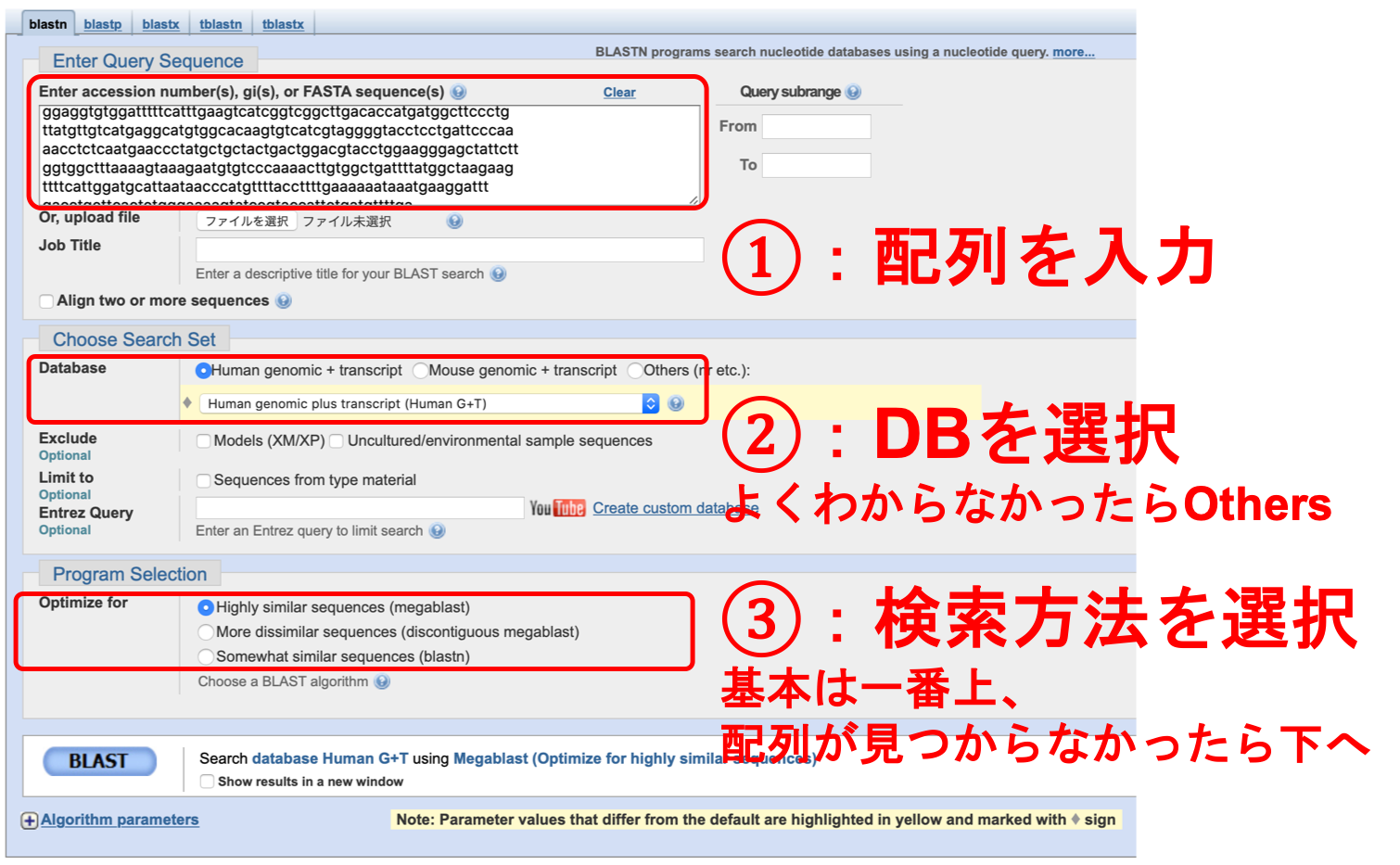
2. クエリ配列を入れた上で、オプション選んで検索
詳細なオプションはBLASTのつかいかたをみてください。
今回はデフォルトオプションで問題ありません。
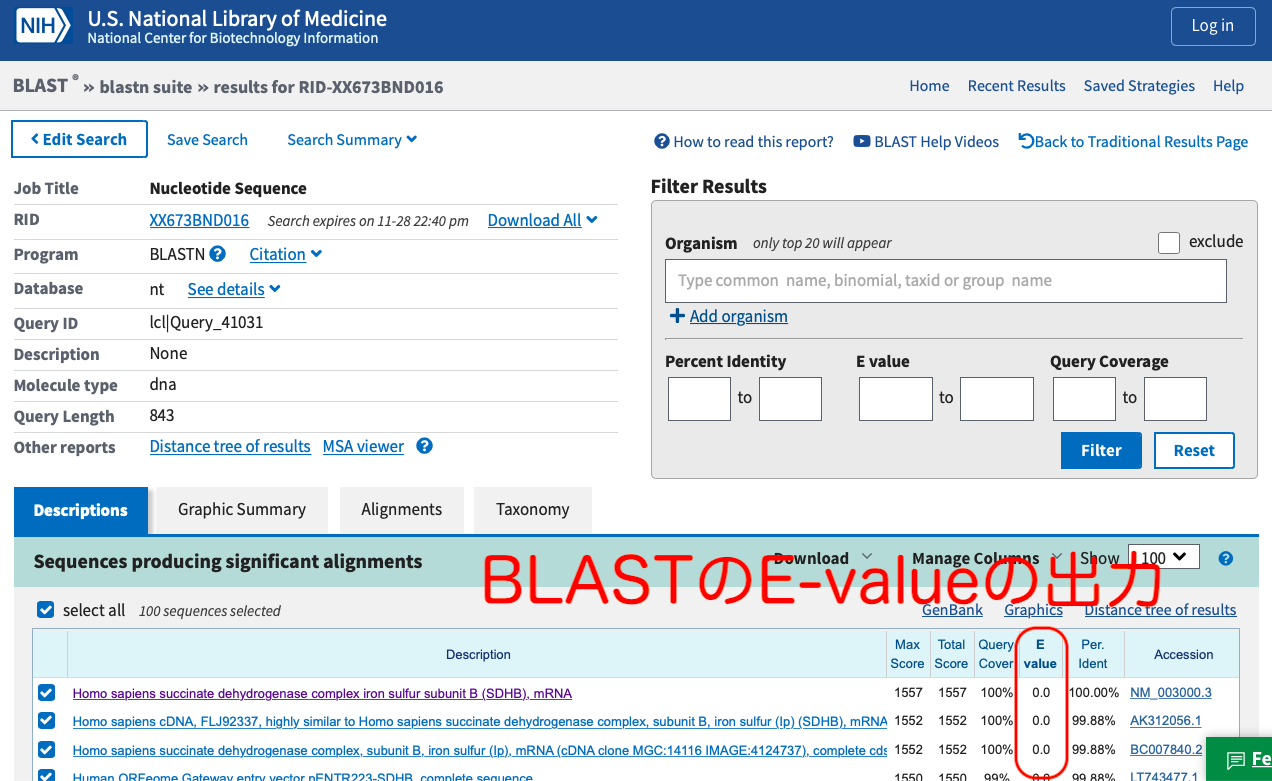
3. 結果を眺める
結果は画面下に出てきます。 E-valueはある程度より小さいと0として丸められてしまうようです。
参考
- E-valueの計算方法(DDBJ)
https://www.ddbj.nig.ac.jp/faq/ja/how-is-e-value-calculated.html
- E-valueの計算方法(わかりやすい)