基本統計量
基本統計量とは?
統計量とは、データの特徴を1つの数値に要約した数値を指します。
様々な統計量がありますが、本ページでは基本統計量としては、以下を扱います。
| 相関係数の種類 | 特徴 |
|---|---|
| 平均値 | 算術平均のこと。いわゆる平均。 |
| 中央値 | 中央の値。平均値より外れ値に引っ張られづらい。 |
| 最小値 | 最小の値。 |
| 最大値 | 最大の値。 |
| 標準偏差 | データのばらつき。 |
| 標準誤差 | 平均値のばらつき。複数回平均値を取得している状況で使用。 |
| 信頼区間 | 母集団の真の統計値が含まれることが一定の確率で信頼できる値の範囲。 (例:95%信頼区間:この範囲に母集団の値が存在すると、95%確信できる値の範囲) |
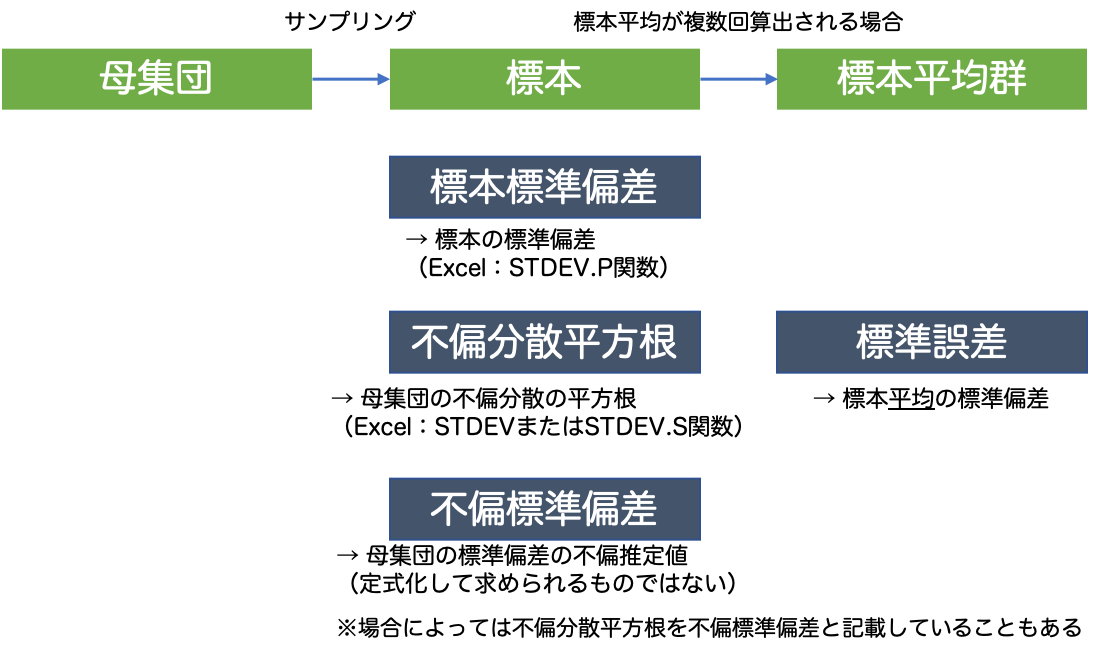
標準偏差はさらにややこしく、「標本標準偏差」「不偏分散平方根」「不偏標準偏差」という概念があり、かつ世の中でよく誤用されています。
以下にまとめました。
例題
RのSleepデータを使用します。
もともとは10人の患者に対して、2種類の薬を使用し、対照薬使用時との睡眠時間の差分を算出したデータです。
各グループのextra列の各種統計値を求めてみます。
#!/usr/bin/env Rscript
data(sleep)
sleep
extra group ID
1 0.7 1 1
2 -1.6 1 2
3 -0.2 1 3
4 -1.2 1 4
5 -0.1 1 5
6 3.4 1 6
7 3.7 1 7
8 0.8 1 8
9 0.0 1 9
10 2.0 1 10
11 1.9 2 1
12 0.8 2 2
13 1.1 2 3
14 0.1 2 4
15 -0.1 2 5
16 4.4 2 6
17 5.5 2 7
18 1.6 2 8
19 4.6 2 9
20 3.4 2 10
例題 - 可視化
以下のPythonコードによって可視化します。
#!/usr/bin/env python
# %matplotlib inline
import seaborn as sns
import matplotlib.pylab as plt
group1 = [0.7, -1.6, -0.2, -1.2, -0.1, 3.4, 3.7, 0.8, 0.0, 2.0]
group2 = [1.9, 0.8, 1.1, 0.1, -0.1, 4.4, 5.5, 1.6, 4.6, 3.4]
sns.distplot(group1, label="Group1")
sns.distplot(group2, label="Group2")
plt.legend()
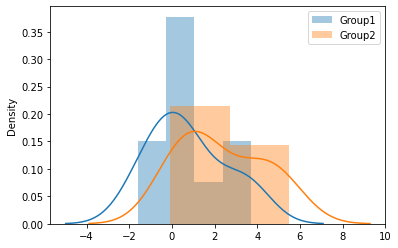
group2の方が全体的に高そうです。他の基礎統計量もみてみます。
ソースコード
# Pythonで基礎統計量のソースコード
Pythonは様々な選択肢があります。
主な選択肢としては、以下の4つがあります。
-
numpy
-
scipy
-
pandas
-
statistics
標準偏差を求める際、numpyだけ標本標準偏差がデフォルトで出力されるので注意してください。
import scipy
import statistics
import numpy as np
import pandas as pd
import scipy.stats as st
group1 = [0.7, -1.6, -0.2, -1.2, -0.1, 3.4, 3.7, 0.8, 0.0, 2.0]
group2 = [1.9, 0.8, 1.1, 0.1, -0.1, 4.4, 5.5, 1.6, 4.6, 3.4]
# 平均値
# => 0.75
print(np.mean(group1))
print(pd.Series(group1).mean())
print(scipy.mean(group1))
print(statistics.mean(group1))
# 中央値
# => 0.35
print(np.median(group1))
print(pd.Series(group1).median())
print(statistics.median(group1))
# 最小値
# => -1.6
print(np.min(group1))
# 最大値
# => 3.7
print(np.max(group1))
# 25%, 75%値
# => -0.175, 1.7
print(np.percentile(group1, 25))
print(np.percentile(group1, 75))
# 標準偏差(不偏分散平方根)
# => 1.7890096577591625
print(statistics.stdev(group1))
print(pd.Series(group1).std())
# 標本標準偏差
# => 1.6972035823671832
print(np.std(group1))
# 平均値の信頼区間
# => (-0.5297804134938644, 0.75, 2.0297804134938646)
def confidence_interval(a, percentile=0.95):
arithmetic_mean = scipy.mean(a)
ci_lower, ci_upper = st.t.interval(percentile, len(a)-1, loc=arithmetic_mean, scale=st.sem(a))
return ci_lower, arithmetic_mean, ci_upper
print(confidence_interval(group1))
# Rで基礎統計量
Rはデフォルトの関数で概ね基礎統計料を求めることができます。
#!/usr/bin/env Rscript
group1 <- c(0.7, -1.6, -0.2, -1.2, -0.1, 3.4, 3.7, 0.8, 0.0, 2.0)
group2 <- c(1.9, 0.8, 1.1, 0.1, -0.1, 4.4, 5.5, 1.6, 4.6, 3.4)
# 平均値: 0.75
print(mean(group1))
# 中央値: 0.52
print(median(group1))
# 最小値: -1.04
print(min(group1))
# 最大値: 1.81
print(max(group1))
# 25%, 75%値: -0.175, 1.7
print(quantile(group1, 0.25))
print(quantile(group1, 0.75))
# 標準偏差(不偏分散平方根): 1.78901
sd(group1)
# (95%)信頼区間: -0.5297804 0.7500000 2.0297804
confidence_interval <- function(x, percentile=0.95) {
result_t_test = t.test(x, conf.level=percentile)
return(c(result_t_test[[4]][1], mean(x), result_t_test[[4]][2]))
}
print(confidence_interval(group1))
その他
特になし