Jonckheere-Terpstra trend検定(ヨンクヒール・タプストラ検定)
Jonckheere-Terpstra trend検定(ヨンクヒール・タプストラ検定)とは?
以下のデータのように、目的変数が連続値の時に使用できる傾向性検定です。
帰無仮説としては各群の中央値が同じであることを仮定します。
例題 - 可視化
Rのライブラリに付属していたテストデータを用いてみます。
#!/usr/bin/env Rscript
set.seed(1234)
g <- rep(1:5, rep(10,5))
x <- rnorm(50)
jonckheere.test(x+0.3*g, g)
x[1:2] <- mean(x[1:2]) # tied data
# ggplotで可視化
library(ggplot2)
df = data.frame(
x=as.factor(g),
y=x+0.3*g
)
ggplot(data=df, aes(group=x, y=y, fill=x)) + geom_boxplot()
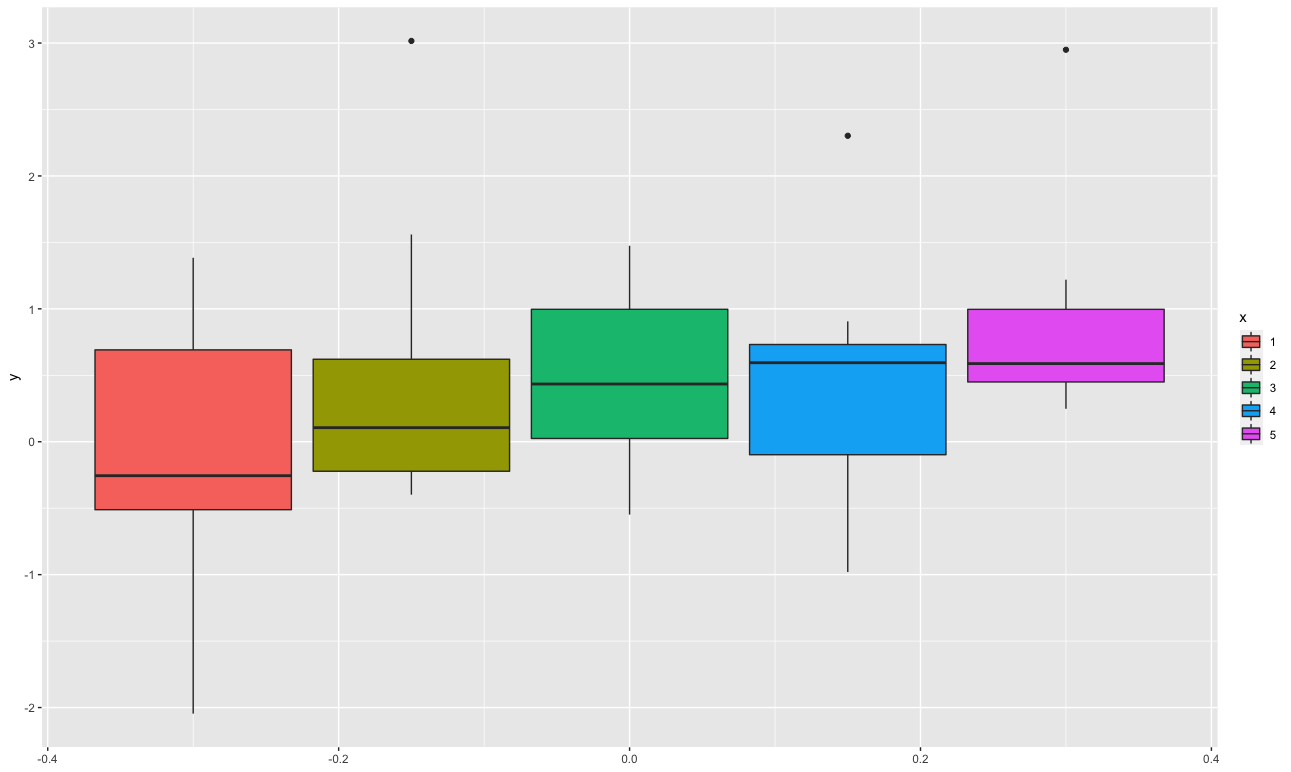
【結果】
パッと見、データの数値が大きくなると値が上がっていることがわかるかと思います。これをヨンクヒール・タプストラ検定で検証していきます。
ソースコード
# Pythonでヨンクヒール・タプストラ検定
ケンドールの順位相関と同じ考え方であり、Pythonでは相当するライブラリがないため、ケンドールの順位相関係数の無相関検定を行い、代用しています。
なお、後述しますが、Pythonのこのライブラリではタイ値の補正を行っています。
#!/usr/bin/env python
import scipy.stats as st
# ここソースコード汚くて申し訳ないです…
x = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5]
y = [-0.164818254, -0.164818254, 1.384441177, -2.045697703, 0.729124689, 0.806055892, -0.27473996, -0.246631856, -0.264451999, -0.590037829, 0.1228073, -0.398386445, -0.176253895, 0.664458817, 1.559494059, 0.489714506, 0.088990494, -0.311195417, -0.23717168, 3.015835178, 1.03408822, 0.409314103, 0.459452128, 1.359589441, 0.206279753, -0.54820491, 1.474755721, -0.123655723, 0.8848617, -0.035948601, 2.302297546, 0.724406921, 0.490559962, 0.698741939, -0.429093469, 0.032380738, -0.980039649, -0.140993192, 0.905706141, 0.73410246, 2.949496265, 0.431357276, 0.644635366, 1.219376998, 0.505659924, 0.531485682, 0.392681807, 0.248014114, 0.976171881, 1.003150043]
# タイ補正あり
st.kendalltau(x, y) # => 0.017403048418730287
# Rでヨンクヒール・タプストラ検定
Rの場合は、いくつかのライブラリでヨンクヒール・タプストラ検定を行うことができます。
ここでは、”clinfun”および”PMCMRplus”というライブラリを使用し、両方の結果を比較してみます。
#!/usr/bin/env Rscript
# データの生成
set.seed(1234)
g <- rep(1:5, rep(10,5))
x <- rnorm(50)
x[1:2] <- mean(x[1:2]) # tied data
# clinfun => タイ補正なし
# install.packages("clinfun")
library("clinfun")
jonckheere.test(x+0.3*g, g) # => 0.01741
# PMCMRplus => タイ補正あり
# install.packages("PMCMRplus")
library(PMCMRplus)
jonckheereTest(x+0.3*g, g) # => 0.0174
タイ値の扱いが異なるため、若干p値が異なります。
このあたりはブログでまとめて頂いている方がおりますので、ご参照ください。
その他
特になし