Steel-Dwass検定(スティール・ドゥワス検定)
Steel-Dwass検定(スティール・ドゥワス検定)
同時に3群以上の差を検定するとき、単純に2群間の検定を行うと、偶然有意差が出てしまう確率(偽陽性;第一種の過誤)が高くなってしまいます。
この確率を制御する方法として、(3群以上を比較する際には)多重比較法が用いられます。
多重比較法にもいろいろありますが、ここでは、スティール・ドゥワス検定を用いた解析手法について述べます。
例題
scikit-posthocsのテストデータを持ってきました。
Pandasで可視化すると以下のようになります。
#!/usr/bin/env python
import pandas as pd
import matplotlib.pylab as plt
df = pd.DataFrame({
"a": [1, 2, 3, 5, 1],
"b": [12, 31, 54, 62, 12],
"c": [10, 12, 6, 74, 11]
})
df.plot(kind="box")
plt.savefig("boxplot.steel-dwass.png")
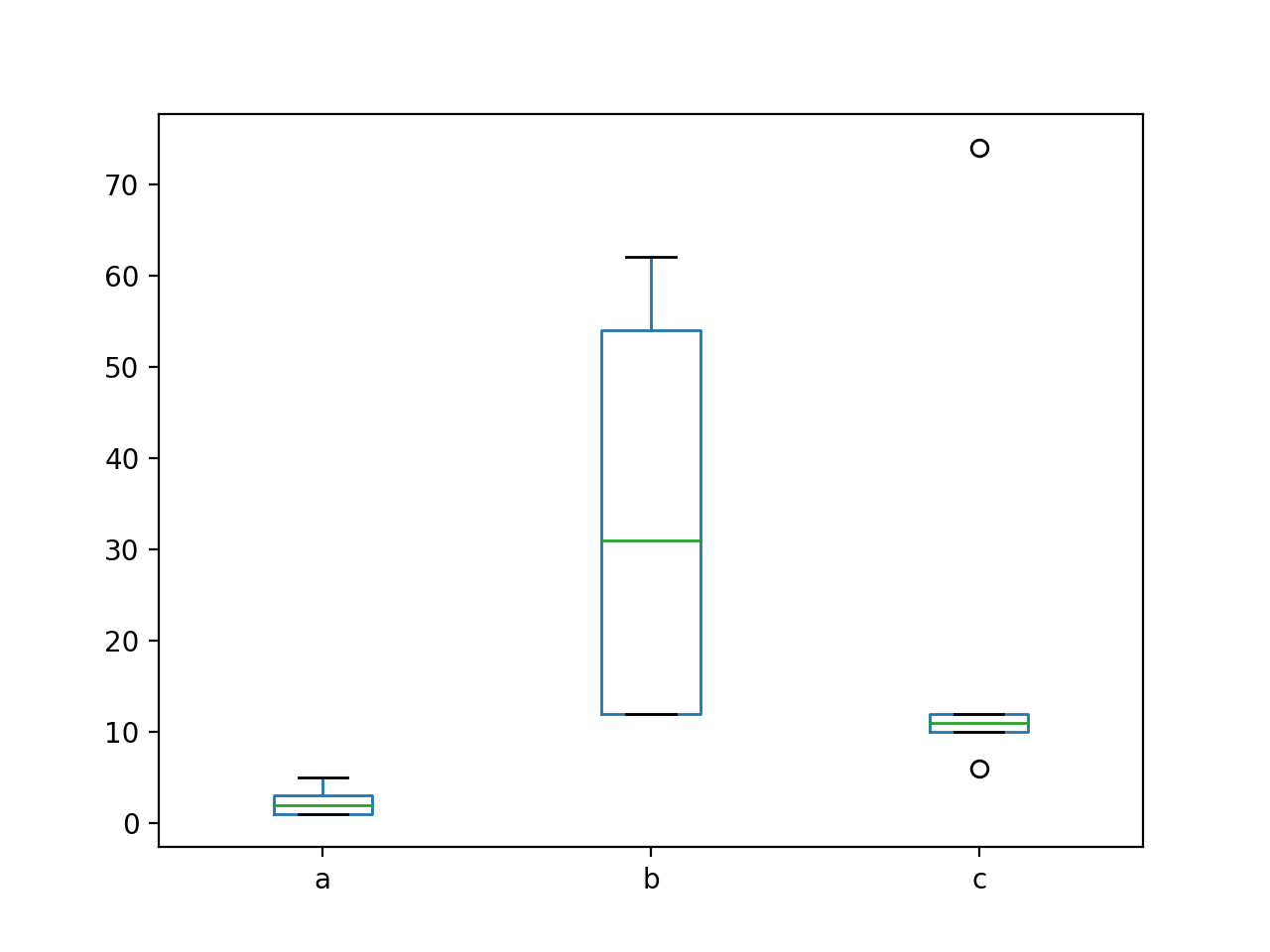
パッと見、aはダントツ低いことがわかると思います。
ソースコード
Steel-Dwass検定も正確検定および近似検定があります。
サンプルサイズが小さい場合(比較する群間の片方が10以下の場合など)は、正確検定を使うべきであると述べています。
# Pythonでスティール・ドゥワス検定
Pythonの場合は scikit-posthocs でスティール・ドゥワス検定を行うことができます。
なお、Scikit-posthocsでは正確検定は行うことができません。
#!/usr/bin/env python
#! pip install scikit-posthocs
import pandas as pd
import scikit_posthocs as sp
x = pd.DataFrame({"a": [1, 2, 3, 5, 1], "b": [12, 31, 54, 62, 12], "c": [10, 12, 6, 74, 11]})
x = x.melt(var_name='groups', value_name='values')
print(x)
sp.posthoc_dscf(x, val_col='values', group_col='groups')
結果は以下のように出力されます。

# Rでスティール・ドゥワス検定
Rの場合は、いくつかのライブラリでスティール・ドゥワス検定を行うことができます。
ちなみに、群馬大の青木先生のページのものは近似法によるものです。
ここでは、正確法も実行することができるライブラリであるNSM3を使用します。
#!/usr/bin/env Rscript
# install.packages("NSM3")
library("NSM3")
values = c(1, 2, 3, 5, 1, 12, 31, 54, 62, 12, 10, 12, 6, 74, 11)
groups = c(1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3)
# デフォルトではMonte Carloが使用される。
# 試行数が10,000未満の場合はExactと同じとなる。
# 再現性確保のためにseedを設定する
set.seed(0)
p_monte = pSDCFlig(values, groups)
print(p_monte$labels) # => "1 - 2" "1 - 3" "2 - 3"
print(p_monte$p.val) # => 0.0090 0.0163 0.3780
# 近似法
p_asymptotic = pSDCFlig(values, groups, method="Asymptotic")
print(p_asymptotic$labels) # => "1 - 2" "1 - 3" "2 - 3"
print(p_asymptotic$p.val) # => 0.02344837 0.02396820 0.35445269
# 正確法
set.seed(0)
p_exact = pSDCFlig(values, groups, method="Exact")
print(p_exact$labels) # => "1 - 2" "1 - 3" "2 - 3"
print(p_exact$p.val) # => 0.008253651 0.015936445 0.375481661
想定通り、1とその他は有意差が認められた。
ただし、正確法はかなり実行時間がかかります。近似法はかなりp値が違うため、サンプルサイズが少ない場合は実行時間を気にするならばモンテカルロ法がよいでしょう。
その他
特になし