主成分分析(PCA)
PCA(Principal Component Analysis, 主成分分析)とは?
多変量解析の手法の1つです。
複数次元あるデータを要約して、データの関係性をわかりやすく要約してくれます。
よくある勘違いですが、クラスタリングと違い、データがどういうクラスターに属するかはわかりません。
PCAによって見た目で明らかにクラスタが分かれる場合もありますが、クラスタ分けはk-meansなどで別途行う必要があります。
例題
中学校のテストデータを作成してみました。データ作成に関しては、以下の仮定を置いてデータを生成しています。
-
国社理数英のデータがある
-
国語、社会、英語は正の相関がある
-
理科、数学は正の相関がある
-
国社英と理数は負の相関がある
Pythonで可視化すると以下のようになります。
#!/usr/bin/env python
#!pip install japanize_matplotlib # プロット中で日本語を使用するためにインストール
import pandas as pd
import seaborn as sns
import japanize_matplotlib
import matplotlib.pyplot as plt
from IPython.display import display
df = pd.DataFrame({
"国語": [55, 28, 48, 49, 66, 49, 45, 36, 64, 34],
"社会": [83, 42, 68, 77, 67, 71, 61, 51, 78, 68],
"数学": [19, 29, 8, 10, 25, 17, 18, 35, 19, 22],
"理科": [51, 52, 33, 45, 46, 39, 36, 52, 33, 60],
"英語": [94, 66, 64, 81, 92, 78, 68, 77, 84, 82]
}, index=["A01", "A02", "A03", "A04", "A05", "A06", "A07", "A08", "A09", "A10"])
display(df.corr()) # => 相関係数(ピアソン)行列をtableとして出力
sns.pairplot(df)
plt.savefig("pairplot.png")
【結果】
google slide上で若干編集し、以下のようにまとめました。
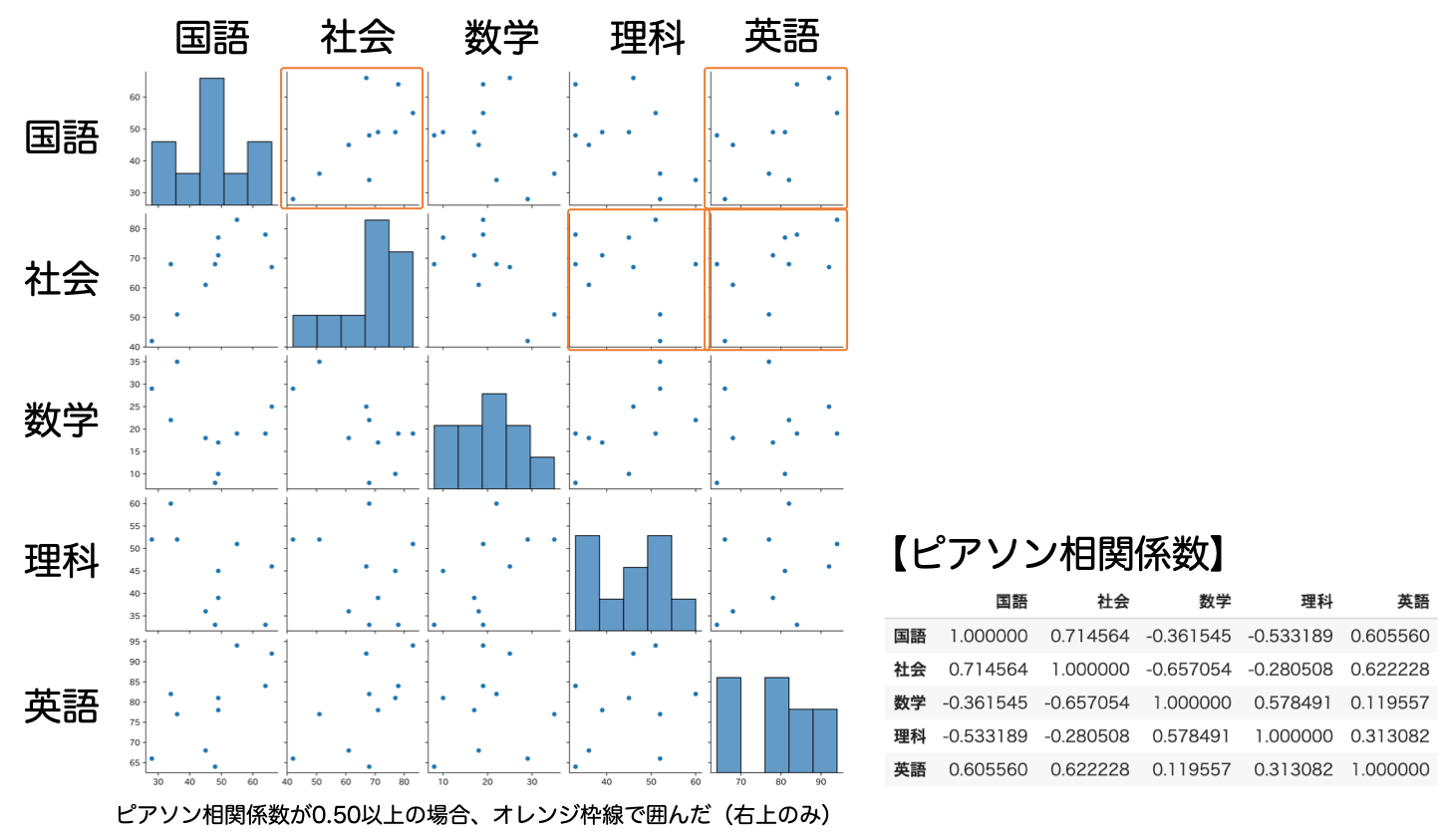
国社英の相関が高いこと、理数の相関が高いことがわかるかと思います。
ソースコード
# PythonでPCA(主成分分析)+ Biplot(バイプロット)
Pythonの場合は scikit-learnでPCAを行うことができます。
以下のソースコードは、①主成分得点、②寄与率、③因子負荷量(バイプロット)の全てを表示するようにしています。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Jupyter上で確認したい場合は必要
# %matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
df = pd.DataFrame({
"国語": [55, 28, 48, 49, 66, 49, 45, 36, 64, 34],
"社会": [83, 42, 68, 77, 67, 71, 61, 51, 78, 68],
"数学": [19, 29, 8, 10, 25, 17, 18, 35, 19, 22],
"理科": [51, 52, 33, 45, 46, 39, 36, 52, 33, 60],
"英語": [94, 66, 64, 81, 92, 78, 68, 77, 84, 82]
}, index=["A01", "A02", "A03", "A04", "A05", "A06", "A07", "A08", "A09", "A10"])
pca = PCA(n_components=2, random_state=0)
df_pca = pd.DataFrame(pca.fit_transform(df))
df_pca.columns = ["PC1", "PC2"]
# 寄与率の表示
pc1_explained_variance_ratio = 100 * pca.explained_variance_ratio_[0]
pc2_explained_variance_ratio = 100 * pca.explained_variance_ratio_[1]
# パーセント表示に変更、小数点1桁まで表示
pc1_explained_variance_ratio = format(pc1_explained_variance_ratio, '.1f')
pc2_explained_variance_ratio = format(pc2_explained_variance_ratio, '.1f')
# 観測変数の寄与度
df_components = pd.DataFrame(pca.components_).T
df_components.index = df.columns
df_components.columns = ["PC1", "PC2"]
# 描画
# メイン
plt.scatter(df_pca["PC1"], df_pca["PC2"])
# 観測変数の寄与度
# Rっぽく
for x, y, text in zip(df_components["PC1"], df_components["PC2"], df_components.index):
plt.arrow(0, 0, x, y, color="red", width=0.025)
plt.text(x, y, text)
plt.xlabel(f"PC1({pc1_explained_variance_ratio}%)")
plt.ylabel(f"PC2({pc2_explained_variance_ratio}%)")
plt.savefig("plt.pca.midterm_test.sklearn.png")
結果は以下のように出力されます。
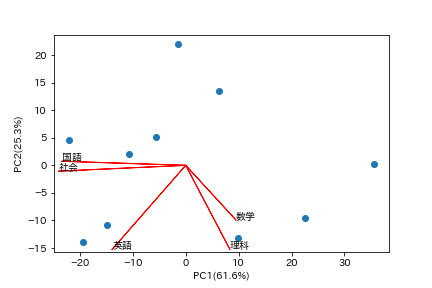
# RでPCA(主成分分析) + Biplot(バイプロット)①
Rの場合は、デフォルトの関数(prcomp())でPCAを行うことができます。
#!/usr/bin/env Rscript
国語 = c(55, 28, 48, 49, 66, 49, 45, 36, 64, 34)
社会 = c(83, 42, 68, 77, 67, 71, 61, 51, 78, 68)
数学 = c(19, 29, 8, 10, 25, 17, 18, 35, 19, 22)
理科 = c(51, 52, 33, 45, 46, 39, 36, 52, 33, 60)
英語 = c(94, 66, 64, 81, 92, 78, 68, 77, 84, 82)
df = data.frame(
国語=国語,
社会=社会,
数学=数学,
理科=理科,
英語=英語
)
rownames(df) = c("A01", "A02", "A03", "A04", "A05", "A06", "A07", "A08", "A09", "A10")
# 日本語表示用
par(family= "HiraKakuProN-W3")
biplot(prcomp(df))
結果は以下のように出力されます。
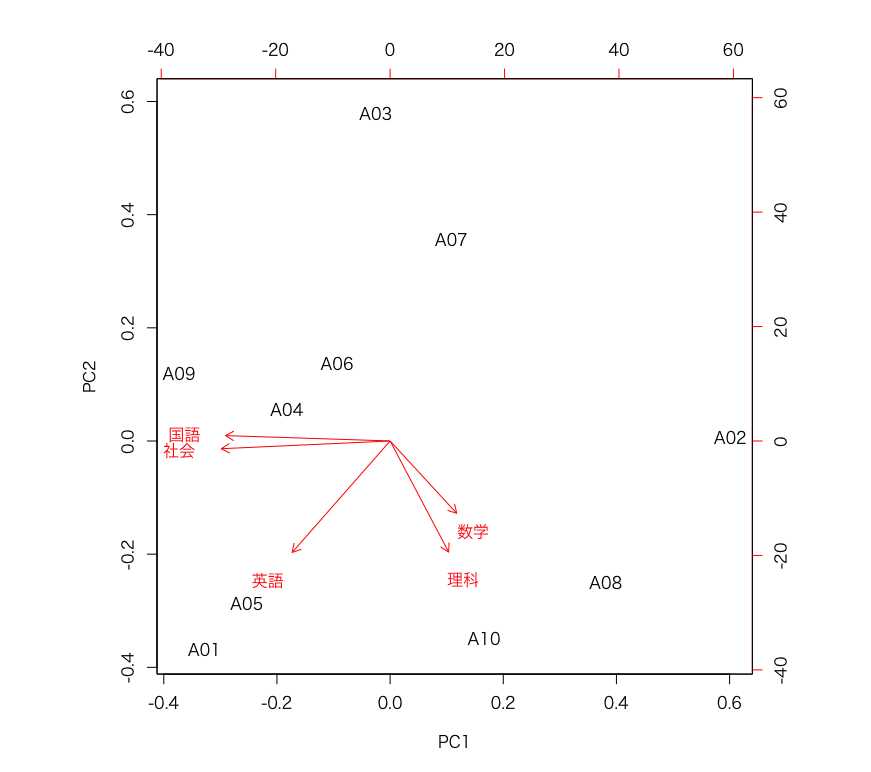
PythonとRの結果を比較すると(Rは変数の正規化?を行っていますが)プロットの位置関係としては同じであることがわかると思います。
(また、irisデータなどを使用すると、Rは場合によってはy軸が逆転することがあります)
# RでPCA(主成分分析) + Biplot(バイプロット)②
ggplot風にPCAしたい場合、ggbiplotというライブラリがあります。[参考]
#!/usr/bin/env Rscript
# 初回のみ
# install.packages("devtools")
# devtools::install_github("vqv/ggbiplot")
library("ggbiplot")
国語 = c(55, 28, 48, 49, 66, 49, 45, 36, 64, 34)
社会 = c(83, 42, 68, 77, 67, 71, 61, 51, 78, 68)
数学 = c(19, 29, 8, 10, 25, 17, 18, 35, 19, 22)
理科 = c(51, 52, 33, 45, 46, 39, 36, 52, 33, 60)
英語 = c(94, 66, 64, 81, 92, 78, 68, 77, 84, 82)
df = data.frame(
国語=国語,
社会=社会,
数学=数学,
理科=理科,
英語=英語
)
rownames(df) = c("A01", "A02", "A03", "A04", "A05", "A06", "A07", "A08", "A09", "A10")
ggbiplot(prcomp(df)) # groupsで簡易に色分けができる
結果は以下のように出力されます。
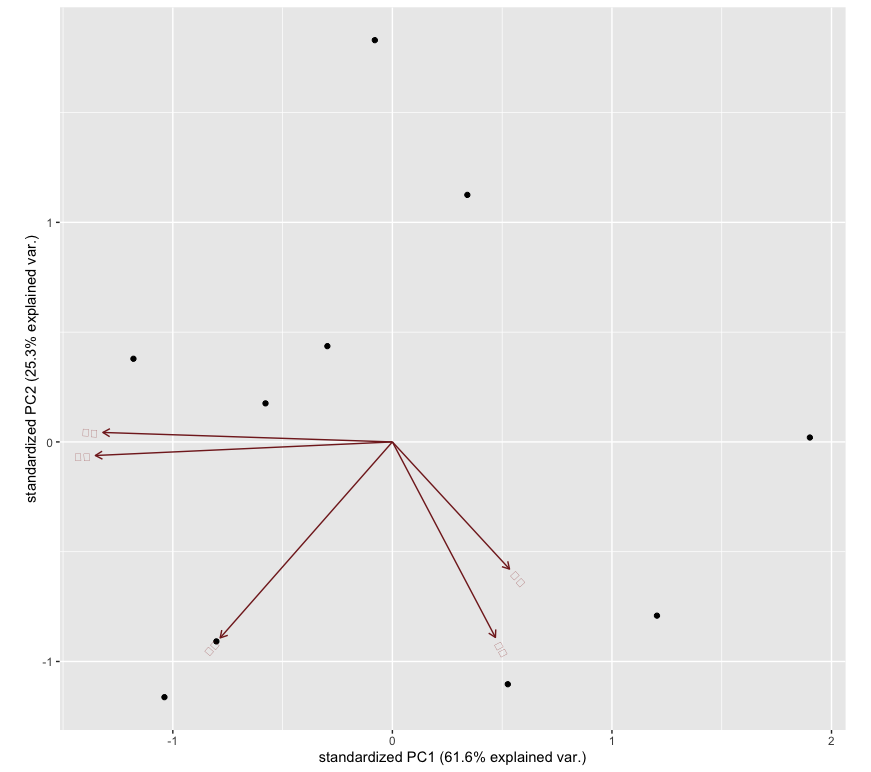
(ggplotで日本語を出力する方法がわかりませんでした…)
Rのデフォルト関数やPythonと同様の値が出ていることがわかるかと思います。
その他
特になし