フィッシャーの正確確率検定
フィッシャーの正確確率検定とは
フィッシャーの正確確率検定はカイ二乗検定の正確検定版です。
カイ二乗検定は「独立性の検定」とも言われます。
この書き方だと難しいですが、個人的には「確率が有意に異なるかを検証する検定」と認識しています。
サンプルサイズが小さいときはこのフィッシャーの正確確率検定を使用してください。
以下、具体例を見てみます。
その前に、同様の検定を以下にまとめます。
| 検定名 | 英語名 | パラメトリック? | 対応 | コメント |
|---|---|---|---|---|
| カイ二乗検定 | Chi-squared test | ノンパラメトリック | 対応なし | サンプルサイズが小さいときはフィッシャーの正確確率検定を使用する |
| フィッシャーの正確確率検定 | Fisher's exact test | パラメトリック | 対応なし | - |
| マクネマー検定 | McNemar test | パラメトリック | 対応あり | 対応ありの際はこの検定を用いる |
例題 - データ
RのTitanicデータを使用します。
本来はいくつかデータがありますが、今回は「男女で生存率に差があるのか?」を検証したいと思います。
#!/usr/bin/env Rscript
df = data.frame(Titanic)
head(df)
# Class Sex Age Survived Freq
# 1 1st Male Child No 0
# 2 2nd Male Child No 0
# 3 3rd Male Child No 35
# 4 Crew Male Child No 0
# 5 1st Female Child No 0
# 6 2nd Female Child No 0
例題 - 可視化
以下のコードによって可視化します。
#!/usr/bin/env Rscript
df = data.frame(Titanic)
male_yes = sum(df[df$Sex == "Male" & df$Survived == "Yes", "Freq"])
male_no = sum(df[df$Sex == "Male" & df$Survived == "No", "Freq"])
female_yes = sum(df[df$Sex == "Female" & df$Survived == "Yes", "Freq"])
female_no = sum(df[df$Sex == "Female" & df$Survived == "No", "Freq"])
print(c(male_yes, male_no, female_yes, female_no)) # => 367, 1364, 344, 126
data = matrix(c(male_yes, male_no, female_yes, female_no), ncol=2)
# 簡易可視化
barplot(
data,
beside=T,
legend.text=c("Yes", "No"),
names.arg=c("Male", "Female"),
col=c("red", "blue")
)
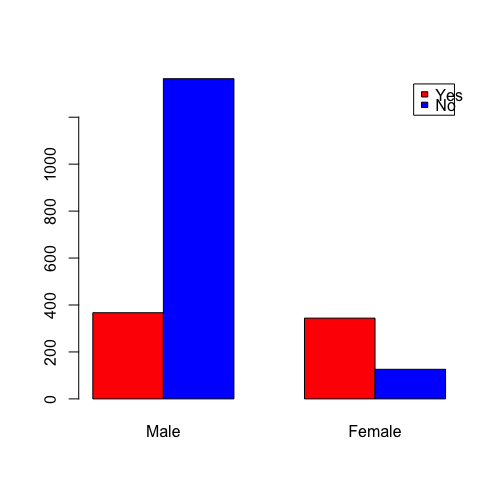
男性のNoの確率(死亡率)が高いことがパッとわかるかと思います。
今回、サンプルサイズを100分の1にした場合も比較します。
帰無仮説を「男女と生存は独立である(関連がない)」としてフィッシャーの正確確率二乗検定を行います。
ソースコード
# フィッシャーの正確確率検定(Python)
#!/usr/bin/env python
import scipy.stats as st # scipy version 1.3.1
data = [[367, 1364], [344, 126]]
print(st.fisher_exact(data)[1]) # => 2.6906937468576903e-96
# 参考値:カイ二乗検定
# st.chi2_contingency(data)[1] # => 7.565461964935766e-101
# フィッシャーの正確確率検定(R)
#!/usr/bin/env Rscript
# 男性_生存、男性_死亡、女性_生存、女性_死亡
data = matrix(c(367, 1364, 344, 126), ncol=2)
print(fisher.test(data)$p.value) # 2.690694e-96
# 参考値:カイ二乗検定
# chisq.test(data)$p.value # => 7.565462e-101
RとPythonでp値は同じですね。
その他
# フィッシャーの正確確率検定とカイ二乗検定の違いについて
サンプルサイズを小さくすると、フィッシャーの正確確率検定とカイ二乗検定の違いがより明確になります。
Pythonで試してみます。
#!/usr/bin/env python
import scipy.stats as st # scipy version 1.3.1
data = [[4, 14], [3, 1]] # Titanicデータを100分の1
print(st.fisher_exact(data)[1]) # => 0.07655502392344488
print(st.chi2_contingency(data)[1]) # => 0.1452510053118262