相関係数(ピアソン相関係数・スピアマン相関係数)
相関係数とは?
2つのデータに対して、線形な関係(片方の数字が大きくなると、もう片方の数字が大きくなる関係性)の強弱を示す指標です。
具体的な例としては、身長と体重などが挙げられます(身長が高くなると体重も比例して高くなる傾向にある)。
よくあることですが、相関は必ずしも因果を表すとは限らないことに注意してください。
今回は、ピアソン相関係数、スピアマン相関係数を取り扱います。それぞれの特徴は以下の通りです。
| 相関係数の種類 | 特徴 |
|---|---|
| ピアソン相関係数 | 値をそのまま相関係数の計算に用いる。シンプルだが、外れ値に引っ張られやすい。 |
| スピアマン相関係数 | 値を順位に直した後、相関係数の計算に用いる。 |
無相関検定とは?
相関係数を求めるときに並行してよく行うこととして、「無相関検定」というものがあります。
帰無仮説は「相関係数の値が0である」で、p値が0.05未満の場合、相関係数の値が0でない → 相関が認められると考えることができます1。
例題
RのSleepデータを使用します。
10人の患者に対して、2種類の薬を使用し、対照薬使用時との睡眠時間の差分を算出したデータです。
もともとのデータは対応のないデータですが、IDが同じ番号が対応しているとして扱っていきます。
#!/usr/bin/env Rscript
data(sleep)
sleep
extra group ID
1 0.7 1 1
2 -1.6 1 2
3 -0.2 1 3
4 -1.2 1 4
5 -0.1 1 5
6 3.4 1 6
7 3.7 1 7
8 0.8 1 8
9 0.0 1 9
10 2.0 1 10
11 1.9 2 1
12 0.8 2 2
13 1.1 2 3
14 0.1 2 4
15 -0.1 2 5
16 4.4 2 6
17 5.5 2 7
18 1.6 2 8
19 4.6 2 9
20 3.4 2 10
例題 - 可視化
以下のコードによって可視化します。
#!/usr/bin/env python
#%matplotlib inline
import pandas as pd
import matplotlib.pylab as plt
group1 = [0.7, -1.6, -0.2, -1.2, -0.1, 3.4, 3.7, 0.8, 0.0, 2.0]
group2 = [1.9, 0.8, 1.1, 0.1, -0.1, 4.4, 5.5, 1.6, 4.6, 3.4]
plt.scatter(group1, group2)
plt.show()
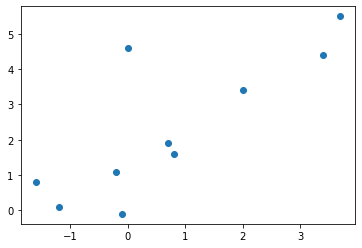
なんとなく相関がありそうな形をしています。
ソースコード
# Pythonで相関係数、および無相関検定
scipy.stats.pearsonrやscipy.stats.spearmanrで相関係数、および無相関検定を行うことができます。
import pandas as pd
import scipy.stats as st
x = [1.81, 0.82, 1.56, -0.48, 0.81, 1.28, -1.04, 0.23, -0.75, 0.14]
y = [0.71, 0.65, -0.2, 0.85, -1.1, -0.45, -0.84, -0.24, -0.68, -0.76]
per, pep = st.pearsonr(x, y)
spr, spp = st.spearmanr(x, y)
print(per) # => 0.2810751389779875
print(pep) # => 0.43146416830894857
print(spr) # => 0.41818181818181815
print(spp) # => 0.22911284098281892
# データフレームから直接相関係数を求めることもできる
pd.DataFrame({"x": x, "y": y}).corr("pearson")
pd.DataFrame({"x": x, "y": y}).corr("spearman")
# Rで相関係数、および無相関検定
#!/usr/bin/env Rscript
x = c(1.81, 0.82, 1.56, -0.48, 0.81, 1.28, -1.04, 0.23, -0.75, 0.14)
y = c(0.71, 0.65, -0.2, 0.85, -1.1, -0.45, -0.84, -0.24, -0.68, -0.76)
# ピアソン相関係数
cor(x, y, method="pearson") # => 0.2810751
# スピアマン相関係数
cor(x, y, method="spearman") # => 0.4181818
# ピアソン相関係数の無相関検定のp値
cor.test(x, y, method="pearson")$p.value # => 0.4314642
# スピアマン相関係数の無相関検定のp値
cor.test(x, y, method="spearman")$p.value # => 0.2324181
その他
-
サンプルサイズが大きくなると、かなり有意になりやすくなります。相関係数も見て議論をしてください。 ↩